getting started
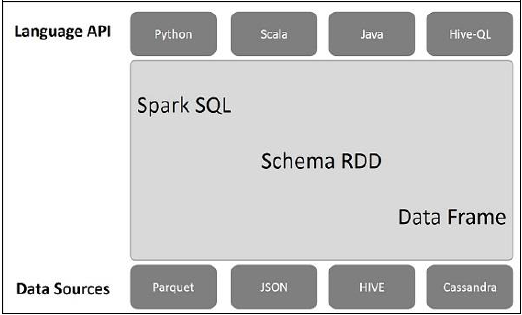
SparkSession
Spark 中所有功能的入口是 SparkSession 类。要创建一个基本的SparkSession 对象, 只需要使用 SparkSession.builder():
1 | // scala |
1 | // java |
1 | # python |
创建 DataFrame
应用程序可以使用 SparkSession从一个现有的 RDD,Hive表或 Spark 数据源创建 DataFrame。下面基于一个 JSON 文件的内容创建一个 DataFrame:
1 | val df = spark.read.json("examples/src/main/resources/people.json") //scala |
DataFrame 操作
DataFrame为 Scala,Java, Python 以及 R 语言中的结构化数据操作提供了一种领域特定语言。
| scala | java | python |
|---|---|---|
df.printSchema() |
df.printSchema(); |
df.printSchema() |
df.select("name") |
df.select("name").show(); |
df.select("name").show(); |
df.select($"name", $"age" + 1).show() |
df.select(col("name"), col("age").plus(1)).show(); |
df.select(df['name'], df['age'] + 1).show() |
df.filter($"age" > 21).show() |
df.filter(col("age").gt(21)).show(); |
df.filter(df['age'] > 21).show() |
df.groupBy("age").count().show() |
df.groupBy("age").count().show() |
df.groupBy("age").count().show() |
1 | /************************** scala*************************/ |
1 | /************************** java*************************/ |
1 | ##################### python ################### |
SQL查询
通过SQL访问数据库,返回一个DataFrame的类型
1 | /*************************** scala *********************************/ |
1 | /*************************** java *********************************/ |
1 | ############################# python ############################### |
全局临时视图
Spark SQL中的临时视图是会话范围的,如果创建它的会话终止,它将消失。如果您希望拥有一个在所有会话之间共享的临时视图并保持活动状态,直到Spark应用程序终止,您可以创建一个全局临时视图。
1 | /********************************* scala *************************************/ |
1 | /********************************* java *************************************/ |
1 | ############################### python ################################ |
创建dataset
Dataset是特定域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作。每个Dataset都有一个称为DataFrame的非类型化的视图,这个视图是行的数据集。上面的定义看起来和RDD的定义类似,DataSet和RDD主要的区别是:DataSet是特定域的对象集合;然而RDD是任何对象的集合。DataSet的API总是强类型的;而且可以利用这些模式进行优化,然而RDD却不行。DataFrame是特殊的Dataset,它在编译时不会对模式进行检测。在未来版本的Spark,Dataset将会替代RDD成为我们开发编程使用的API(注意,RDD并不是会被取消,而是会作为底层的API提供给用户使用)。
1 | // scala |
1 | // java |
与RDD互相转换
Spark SQL 支持两种不同的方法将RDDs 转换成 Datasets.
??????????????????????????????????????????
聚合函数
DataFrame可以使用聚合函数,例如count()、max()等
自定义聚合函数
使用UserDefinedAggregateFunction a自定义聚合函数。
1 |