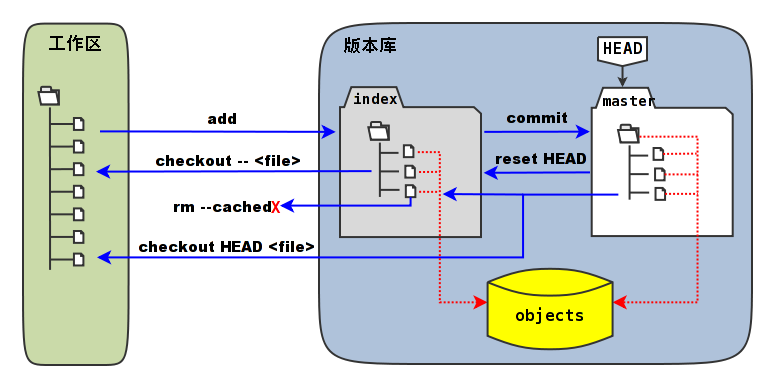
简介
Git 和其它版本控制系统(包括 Subversion 和近似工具)的主要差别在于 Git 对待数据的方法。
大部分版本控制系统,例如(CVS、Subversion、Perforce、Bazaar 等等),采用增量文件系统,存储每个文件版本的差异;
Git 更像是把数据看作是对小型文件系统的一组快照。 每次你提交更新,它主要对当时的全部文件制作一个快照并保存这个快照的索引。 为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件;如果文件发生修改,Git 将存储该文件全部内容。