Map/Reduce 是一个分布式运算程序的编程框架,Map/Reduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。每个Map/Reduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。一个Map/Reduce作业的输入和输出类型如下所示:
(input) <k1, v1> -> map-> <k2, v2> -> Shuff-> <k2, list[v2]> -> reduce -> <k3, v3> (output)
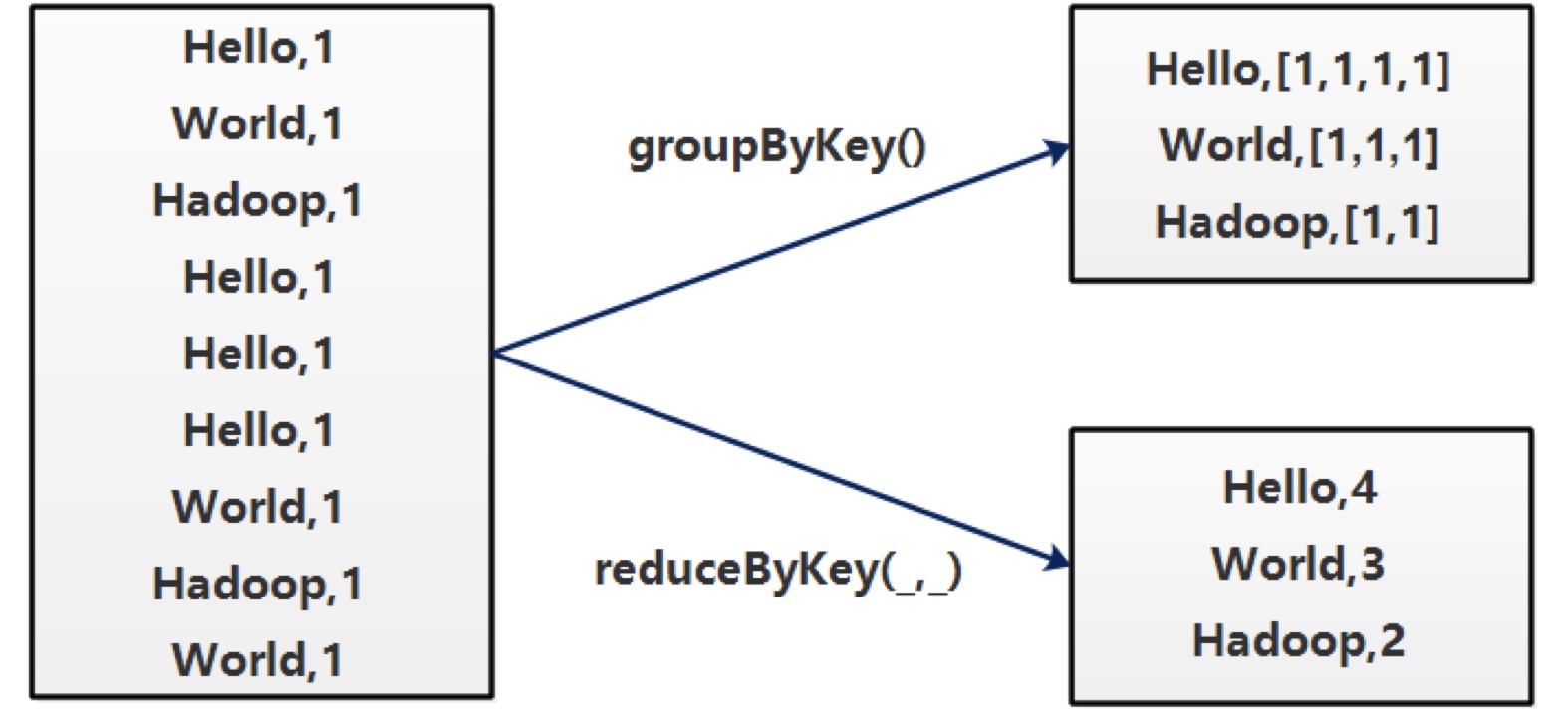
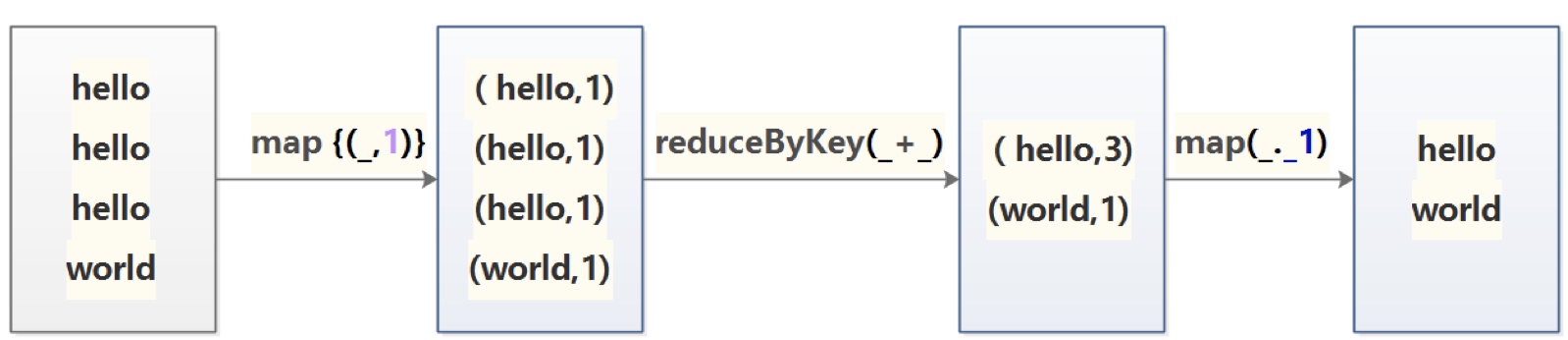
简单在于其编程模型只包含map和reduce两个过程,map的主要输入是一对<key , value>值,经过map计算后输出一对<key , value>值;然后将相同key合并,形成<key , value集合>;再将这个<key , value集合>输入reduce,经过计算输出零个或多个<key , value>对。
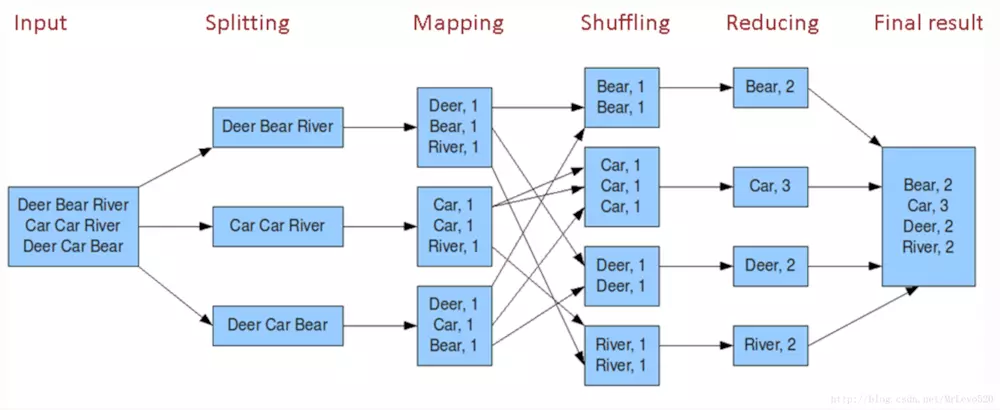
原理
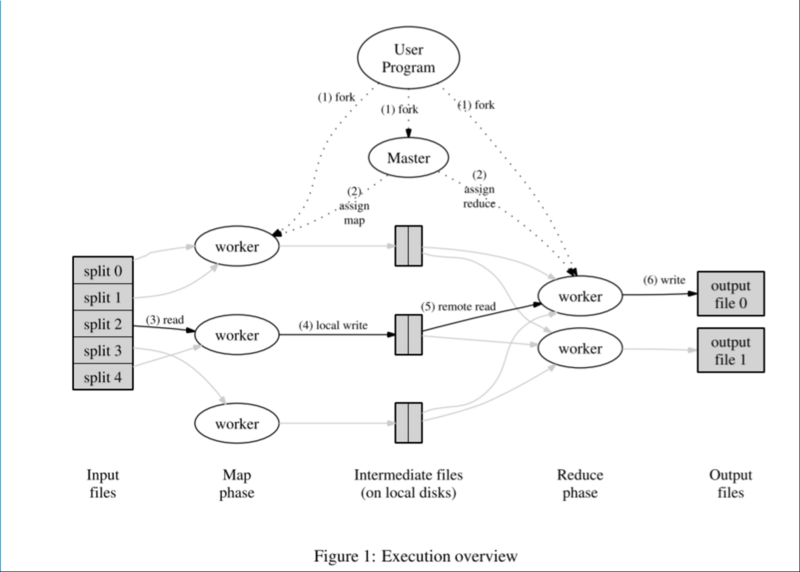
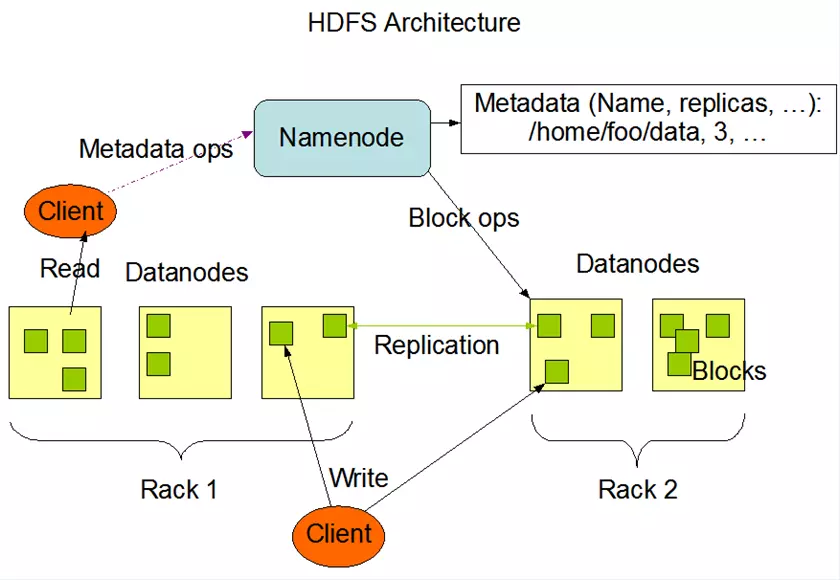
系统中有两类主要的进程节点:master(单点),worker(多个)。其中,worker根据不同的计算任务,又分为map worker(对应上图中的Map phase)、reduce worker(对应上图中的Reduce phase)。
master是系统的中心节点,负责为worker节点分配计算任务,同时监控worker节点的状态。如果某个worker计算太慢,或者宕机,master会将该worker进程负责的计算任务转移到其他进程。worker包括Map与Reduce
- 首先将文件分割成
<key,value>的键值对。Map通过RecordReader读取Input的<key,value>对,map根据用户自定义的任务,运行完毕后,输出另外一系列<key,value>, Shuffle阶段需要从所有map主机上把相同的key的key value对组合在一起,(也就是这里省去的Combine阶段)。Partitioner组件会把key放进一个hash函数里,然后得到结果。如果两个key的哈希值 一样,他们的<key,value>对就被放到同一个reduce函数里。我们也把分配到同一个reduce函数里的<key,value>对叫做一个reduce partition。reduce()函数以key及对应的value列表作为输入,按照用户自己的程序逻辑,经合并key相同的value值后,产 生另外一系列<key,value>对作为最终输出写入HDFS。